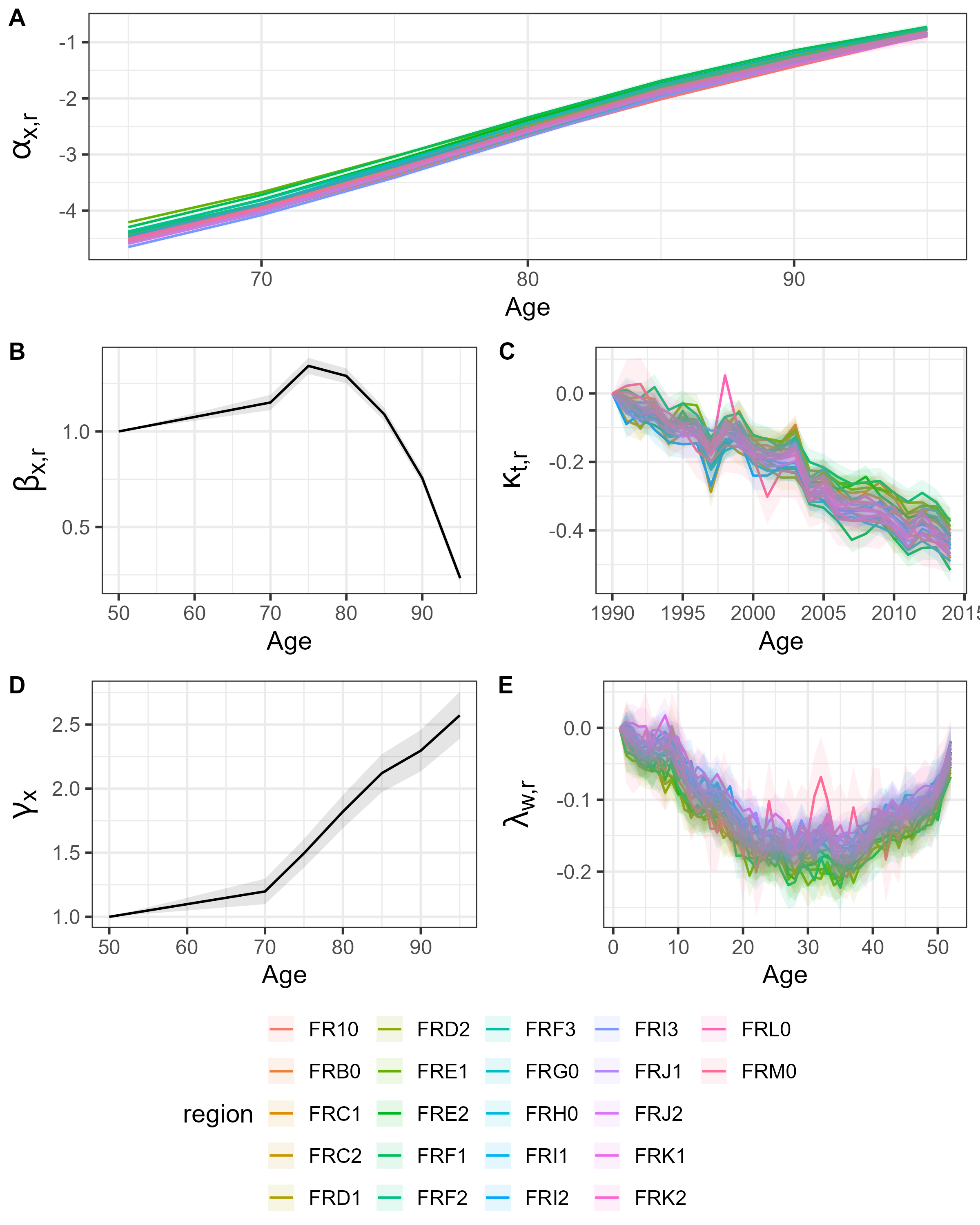
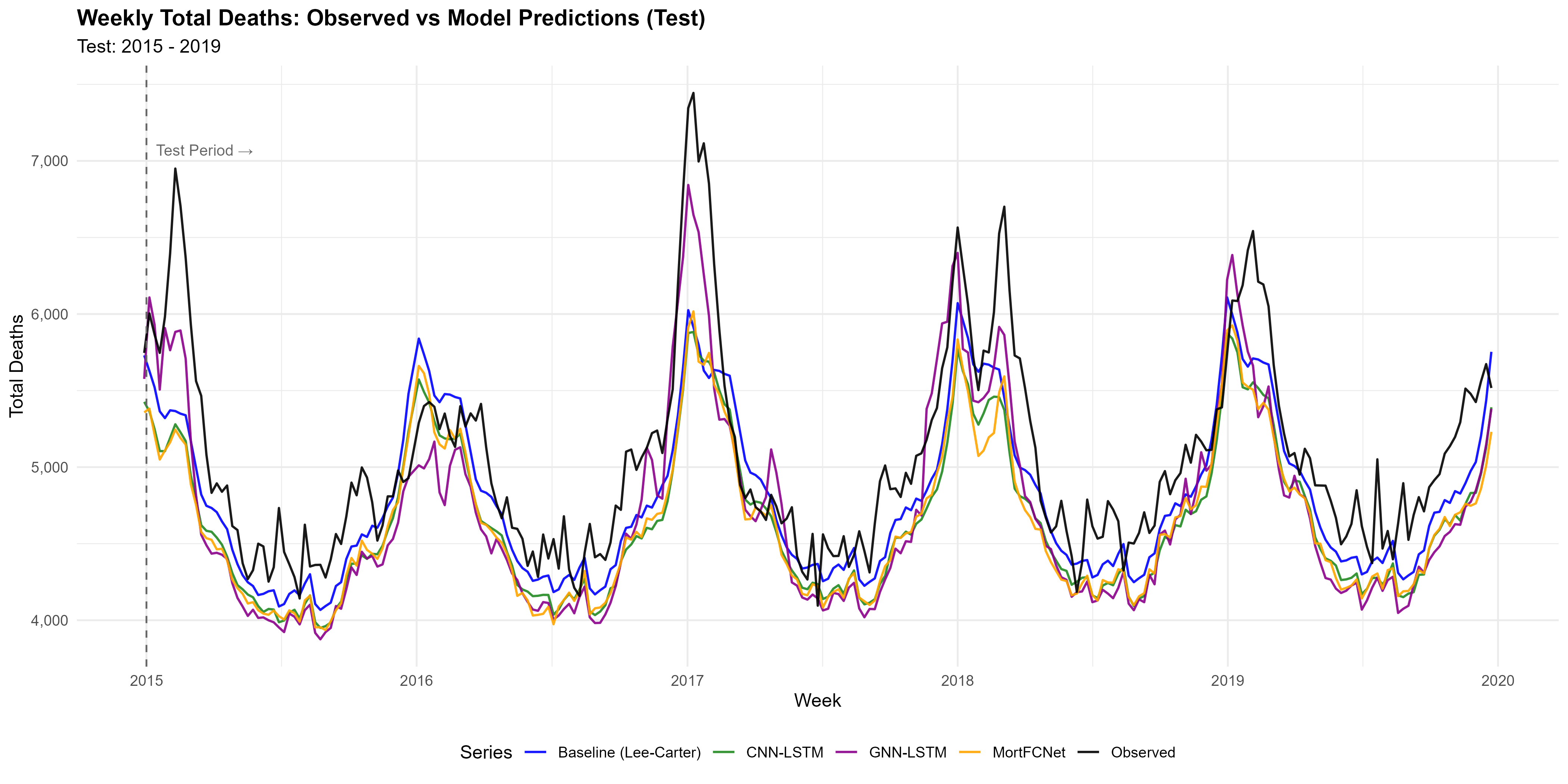
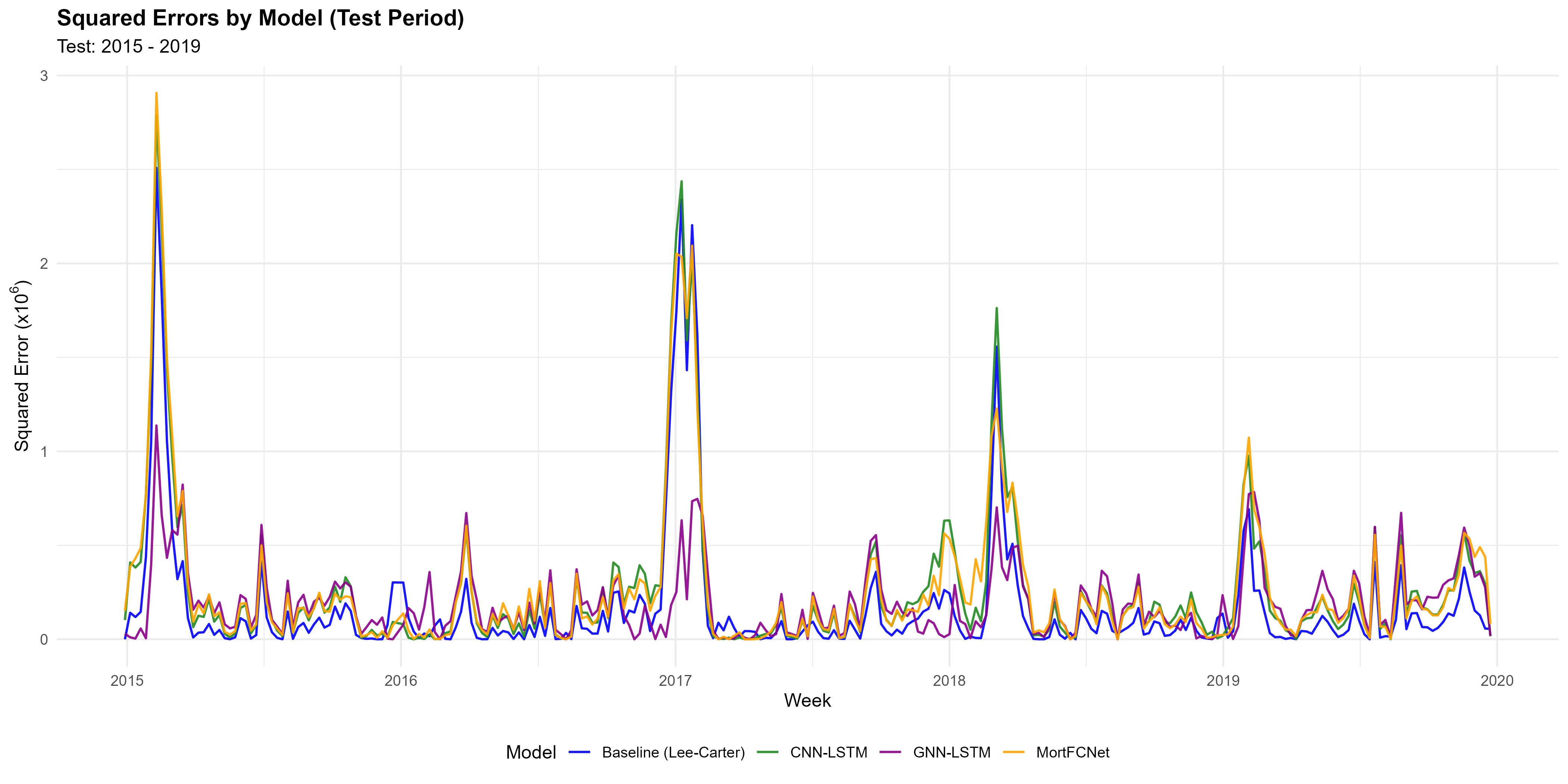
Climate extremes — heatwaves, cold spells, and poor air quality — cause sharp, measurable increases in mortality, especially among older and medically vulnerable people. Accounting for these climate-driven shocks is essential to separate them from baseline seasonal and demographic trends.As a baseline, we start with a purely statistical mortality model that captures patterns across age, time, and season, but does not incorporate any external drivers. Let $D_{x,t,w,r}$ denote the total number of deaths in region $r$ for age group $x$ during ISO week $w$ of year $t$, and $E_{x,t,w,r}$ the corresponding exposure-to-risk. We assume that the deaths follow a negative binomial distribution: \begin{align} D_{x,t,w,r} \sim \text{NB}\Big(E_{x,t,w,r} \cdot \mu_{x,t,w,r}, \phi_{x,r}\Big), \end{align} where $\mu_{x,t,w,r}$ is the weekly mortality rate and $\phi_{x,r}$ is the dispersion parameter. The weekly seasonal model is, \begin{align} \ln(\mu_{x,t,w,r}) = \alpha_{x,r} + \beta_x \kappa_{t,r} + \gamma_x \lambda_{w,r}, \end{align} where $\alpha_{x,r}$ represents baseline mortality for age $x$ in region $r$, $\kappa_{t,r}$ captures long-term trends, and $\lambda_{w,r}$ represents seasonal variation. Age-specific coefficients $\beta_x$ and $\gamma_x$ represent responsiveness to these effects. While this model captures statistical patterns in mortality, it is limited because it does not account for exogenous factors such as climate, which can drive short-term deviations and delayed effects in mortality.Fitted model parametersAfter fitting the baseline weekly mortality model, we examined the residuals to identify weeks when mortality was unusually high or low. We define the log-mortality residuals as \begin{equation} R_{x,t,w,r} = \log\left(\frac{D_{x,t,w,r}}{E_{x,t,w,r}}\right) - \log \hat{\mu}_{x,t,w,r}, \end{equation} where $D_{x,t,w,r}$ and $E_{x,t,w,r}$ are the observed deaths and exposures, and $\hat{\mu}_{x,t,w,r}$ is the baseline prediction. These residuals capture deviations from expected mortality that may be influenced by climate. To forecast weekly mortality we follow a two-step procedure: (1) forecast the latent mortality index $\kappa_{t,r}$ as a region-specific random walk with drift, and (2) plug the simulated $\hat{\kappa}_{t+h,r}$ into the fitted weekly model to obtain predicted weekly rates. Formally, \begin{equation} \kappa_{t,r} = \kappa_{t-1,r} + \mu_r + \epsilon_{t,r}, \qquad \epsilon_{t,r} \sim \mathcal{N}(0,\sigma_r^2). \end{equation} We estimate $\mu_r$ and $\sigma_r^2$ from historical data and simulate future innovations $\epsilon_{t+h,r}$ (Monte Carlo) to generate $\hat{\kappa}_{t+h,r}$ for $h=1,\dots,H$. The predicted weekly force of mortality is then \begin{equation} \log \hat{\mu}_{x,t+h,w,r} = \hat{\alpha}_{x,r} + \hat{\beta}_x\,\hat{\kappa}_{t+h,r} + \hat{\gamma}_x\,\hat{\lambda}_{w+h,r}. \end{equation} The seasonal component $\hat{\lambda}_{w,r}$ is held fixed from the training fit. Monte Carlo samples of $\hat{\kappa}$ provide forecast uncertainty for $\hat{\mu}$.Forecasted $\kappa_{t,r}$ valuesTo account for climate-driven deviations in mortality, we model the log-mortality residuals using a combination of Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks. The CNN extracts short-term patterns from sequences of weekly climate covariates, such as temperature, humidity, and air pollution. For each layer, a 1D convolution is applied, followed by a non-linear activation and normalization, producing feature maps that summarize local temporal correlations. The LSTM then takes these CNN features as input and models longer-term dependencies in the residuals, learning how past climate patterns influence future mortality deviations. A 1D CNN extracts short-term features from weekly climate sequences using learned kernels, ReLU activation, batch normalization, and dropout: \begin{align} \mathbf{Z}^{(k)} &= \mathbf{H}^{(k-1)} \ast \mathbf{W}^{(k)} + \mathbf{b}^{(k)}, \\ \mathbf{H}^{(k)} &= \operatorname{Dropout}_{0.1}\big(\operatorname{BatchNorm}(\operatorname{ReLU}(\mathbf{Z}^{(k)}))\big), \end{align} Here $\mathbf{H}^{(0)}=\mathbf{X}$ denotes the input sequence of weekly climate covariates, $\ast$ is 1D convolution, $\mathbf{W}^{(k)}$ and $\mathbf{b}^{(k)}$ are convolution kernel weights and biases, $\operatorname{ReLU}(x)=\max(0,x)$, and $\operatorname{Dropout}_{0.1}$ denotes dropout with rate 0.1. The final output $\mathbf{H}^{(\text{final})}$ summarizes local temporal patterns and feeds into the recurrent layers. An LSTM is a recurrent neural network variant that uses gated memory cells (input, forget, and output gates) to learn and retain long-range dependencies in sequential data. To model longer-range dependencies we use an LSTM that maintains a cell $\mathbf{c}_t$ and gated updates: \begin{align} \mathbf{f}_t &= \sigma(\mathbf{W}^{(f)}\mathbf{x}_t + \mathbf{V}^{(f)}\mathbf{h}_{t-1} + \mathbf{b}^{(f)}),\\ \mathbf{i}_t &= \sigma(\mathbf{W}^{(i)}\mathbf{x}_t + \mathbf{V}^{(i)}\mathbf{h}_{t-1} + \mathbf{b}^{(i)}),\\ \mathbf{o}_t &= \sigma(\mathbf{W}^{(o)}\mathbf{x}_t + \mathbf{V}^{(o)}\mathbf{h}_{t-1} + \mathbf{b}^{(o)}),\\ \mathbf{c}_t &= \mathbf{f}_t \odot \mathbf{c}_{t-1} + \mathbf{i}_t \odot \tanh(\mathbf{W}^{(r)}\mathbf{x}_t + \mathbf{V}^{(r)}\mathbf{h}_{t-1} + \mathbf{b}^{(r)}),\\ \mathbf{h}_t &= \mathbf{o}_t \odot \tanh(\mathbf{c}_t), \end{align} Here $\mathbf{x}_t$ denotes the CNN-derived input feature vector at time $t$, $\sigma(\cdot)$ is the sigmoid function, $\odot$ the element-wise product, and $\mathbf{W}^{(\cdot)},\mathbf{V}^{(\cdot)},\mathbf{b}^{(\cdot)}$ are learnable weight matrices and bias vectors; $\mathbf{h}_t$ and $\mathbf{c}_t$ are the hidden and cell states, respectively.A graph neural network (GNN) learns node-level representations by iteratively aggregating and transforming information from each node's neighbors, allowing the model to capture spatial dependencies between regions. Using self-loops $\tilde{A}=A+I$ and degree matrix $\tilde{D}_{ii}=\sum_j\tilde{A}_{ij}$, a normalized graph convolution layer is: \begin{align} \tilde{A} &= A + I, \\ \tilde{D}_{ii} &= \sum_j \tilde{A}_{ij}, \\ \mathbf{H}^{(k)} &= \sigma\big(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\,\mathbf{H}^{(k-1)}\,\mathbf{W}^{(k)}\big), \end{align} Here $A\in\{0,1\}^{n\times n}$ is the adjacency matrix (with $A_{ij}=1$ when regions $i$ and $j$ are connected) and $\mathbf{H}^{(0)}$ denotes node features initialized from the CNN/LSTM outputs. The final node embeddings $\mathbf{H}^{(\mathrm{final})}$ are pooled (e.g. mean or attention) to obtain a spatial summary $\mathbf{g}$, which is concatenated with the LSTM hidden states $\mathbf{h}_t$ and passed to the prediction head.MortFCNet uses a Gated Recurrent Unit (GRU) to encode temporal features, followed by three fully connected layers that progressively transform the GRU hidden state into the model prediction. Compactly: \begin{align} z_t &= \sigma\big(W^{(z)}x_t + U^{(z)}h_{t-1} + b^{(z)}\big),\\ r_t &= \sigma\big(W^{(r)}x_t + U^{(r)}h_{t-1} + b^{(r)}\big),\\ \tilde{h}_t &= \tanh\big(W^{(h)}x_t + U^{(h)}(r_t \odot h_{t-1}) + b^{(h)}\big),\\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t,\\ f^{(1)} &= \phi\big(W^{(1)}h_t + b^{(1)}\big),\\ f^{(2)} &= \phi\big(W^{(2)}f^{(1)} + b^{(2)}\big),\\ \hat{y} &= W^{(3)}f^{(2)} + b^{(3)}, \end{align} where $\phi(\cdot)$ is a pointwise non-linearity (e.g. ReLU) and $\hat{y}$ is the network output. Here $x_t$ denotes the input features at time $t$ (e.g. temporal or concatenated spatio-temporal features), $h_t$ the GRU hidden state, and $\hat{y}$ the predicted scalar output used for the mortality adjustment.These figures show that all proposed models improve upon the baseline (Lee–Carter) in the test period 2015–2019. In the top panel, the deep learning models track the observed weekly deaths more closely, particularly around seasonal peaks, reducing the systematic underestimation visible in the baseline. The bottom panel confirms this improvement quantitatively: squared errors are generally lower and less extreme for the proposed models, with fewer and smaller error spikes during high-mortality weeks. Overall, this indicates that incorporating temporal and structural information allows the models to better capture mortality dynamics and outperform the traditional baselineObserved vs. Model Predictions (Test: 2015–2019).Squared errors (Test period). Larger values indicate greater extreme errors.
Model
Train (1990–2014)
Test (2015–2019)
Baseline
0.2132
0.2057
MortFCNet
0.2075
0.2042
CNN-LSTM
0.2055
0.2027
GNN-LSTM
0.2053
0.2037
Table: Mean absolute error on training and test periods (lower is better); values computed on weekly totals.